
























Учёные из Университета Претории (ЮАР) разработали новый способ выявления изменений в PDF-документах.
Их прототип анализирует так называемые file page objects — это такие внутренние структуры файла, где хранится всё: от текста и картинок до метаданных.

PDF-формат давно стал стандартом в деловой переписке, поэтому неудивительно, что его часто используют мошенники — например, чтобы подделывать договоры или внедрять вредоносный код.
Сегодня редактировать PDF может кто угодно: есть и Adobe Acrobat, и куча онлайн-редакторов. Поэтому важно уметь быстро определять, менялся ли документ — и если да, то как именно. Обычно для защиты PDF используют водяные знаки и хеши. Но эти подходы работают только с тем, что видно на глаз — текстом и изображениями. Если же злоумышленник подменил метаданные, добавил скрипт или изменил цифровую подпись, такие методы это не отловят.
К тому же, даже небольшое изменение меняет хеш-файл целиком — и непонятно, что именно было затронуто. А это неудобно, особенно в юридически важных документах.
Что придумали в Претории
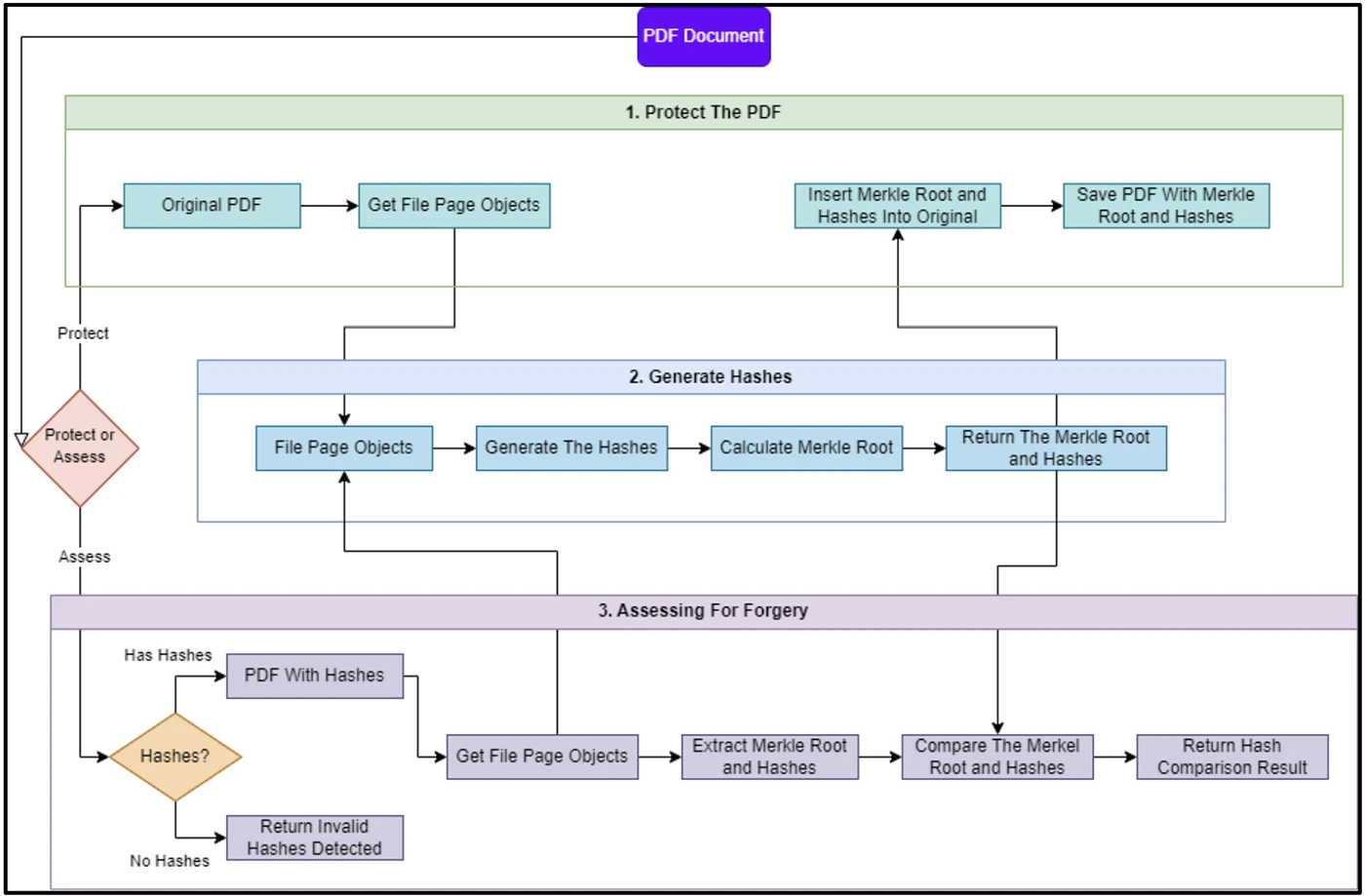
Новый прототип работает на Python и использует библиотеки PDFRW, hashlib и Merkly. Вот как он устроен:
Главное достоинство — точность. Система может указать не только, что файл изменился, но и какую именно страницу и какой участок (в пределах 256 байт) тронули. Также покажет, если были переписаны метаданные.
Пока работает лучше всего с Adobe Acrobat Прототип тестировали на файлах, изменённых в Adobe Acrobat, и в этих случаях он отрабатывал отлично. Теоретически, он должен справляться и с другими редакторами — потому что «защищённые» PDF создаются единообразно через PDFRW, — но это ещё предстоит проверить.
Важное ограничение: систему нельзя применить к «обычным» PDF-документам — сначала их нужно защитить через этот же инструмент. И пока он не умеет отслеживать, скажем, смену шрифта или вставку JavaScript. Тем не менее даже в таком виде инструмент может стать отличной основой для будущих решений в области цифровой гигиены и защиты документов.
Их прототип анализирует так называемые file page objects — это такие внутренние структуры файла, где хранится всё: от текста и картинок до метаданных.
PDF-формат давно стал стандартом в деловой переписке, поэтому неудивительно, что его часто используют мошенники — например, чтобы подделывать договоры или внедрять вредоносный код.
Сегодня редактировать PDF может кто угодно: есть и Adobe Acrobat, и куча онлайн-редакторов. Поэтому важно уметь быстро определять, менялся ли документ — и если да, то как именно. Обычно для защиты PDF используют водяные знаки и хеши. Но эти подходы работают только с тем, что видно на глаз — текстом и изображениями. Если же злоумышленник подменил метаданные, добавил скрипт или изменил цифровую подпись, такие методы это не отловят.
К тому же, даже небольшое изменение меняет хеш-файл целиком — и непонятно, что именно было затронуто. А это неудобно, особенно в юридически важных документах.
Что придумали в Претории
Новый прототип работает на Python и использует библиотеки PDFRW, hashlib и Merkly. Вот как он устроен:
- Сначала PDF нужно “защитить”. Программа читает файл, находит все page objects и создаёт уникальные хеши для каждой страницы, разбивая её содержимое на кусочки по 256 байт. Эти хеши строятся по принципу дерева Меркла: есть “листья” (для каждого блока) и “корень” (общий хеш всей страницы).
- Также отдельно хешируется сам объект страницы и метаданные всего документа. Чтобы избежать ложных срабатываний, некоторые части пропускаются — они могут меняться от редактора к редактору и не несут смысла.
- Все хеши прячутся внутри документа — в специальные скрытые поля. После этого сохраняется новая версия PDF — уже “защищённая”.
- Если потом нужно проверить файл на изменения, программа достаёт из него все сохранённые хеши, заново рассчитывает новые — и сравнивает. Если что-то не совпадает, значит, документ менялся.
Главное достоинство — точность. Система может указать не только, что файл изменился, но и какую именно страницу и какой участок (в пределах 256 байт) тронули. Также покажет, если были переписаны метаданные.
Пока работает лучше всего с Adobe Acrobat Прототип тестировали на файлах, изменённых в Adobe Acrobat, и в этих случаях он отрабатывал отлично. Теоретически, он должен справляться и с другими редакторами — потому что «защищённые» PDF создаются единообразно через PDFRW, — но это ещё предстоит проверить.
Важное ограничение: систему нельзя применить к «обычным» PDF-документам — сначала их нужно защитить через этот же инструмент. И пока он не умеет отслеживать, скажем, смену шрифта или вставку JavaScript. Тем не менее даже в таком виде инструмент может стать отличной основой для будущих решений в области цифровой гигиены и защиты документов.
Для просмотра ссылки необходимо нажать
Вход или Регистрация


